Ease of use
Usable in Java, Scala, Python, and R.
MLlib fits into Spark's APIs and interoperates with NumPy in Python (as of Spark 0.9) and R libraries (as of Spark 1.5). You can use any Hadoop data source (e.g. HDFS, HBase, or local files), making it easy to plug into Hadoop workflows.
.load("hdfs://...")
model = KMeans(k=10).fit(data)
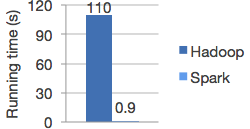
Performance
High-quality algorithms, 100x faster than MapReduce.
Spark excels at iterative computation, enabling MLlib to run fast. At the same time, we care about algorithmic performance: MLlib contains high-quality algorithms that leverage iteration, and can yield better results than the one-pass approximations sometimes used on MapReduce.
Runs everywhere
Spark runs on Hadoop, Apache Mesos, Kubernetes, standalone, or in the cloud, against diverse data sources.
You can run Spark using its standalone cluster mode, on EC2, on Hadoop YARN, on Mesos, or on Kubernetes. Access data in HDFS, Apache Cassandra, Apache HBase, Apache Hive, and hundreds of other data sources.

Algorithms
MLlib contains many algorithms and utilities.
ML algorithms include:
- Classification: logistic regression, naive Bayes,...
- Regression: generalized linear regression, survival regression,...
- Decision trees, random forests, and gradient-boosted trees
- Recommendation: alternating least squares (ALS)
- Clustering: K-means, Gaussian mixtures (GMMs),...
- Topic modeling: latent Dirichlet allocation (LDA)
- Frequent itemsets, association rules, and sequential pattern mining
ML workflow utilities include:
- Feature transformations: standardization, normalization, hashing,...
- ML Pipeline construction
- Model evaluation and hyper-parameter tuning
- ML persistence: saving and loading models and Pipelines
Other utilities include:
- Distributed linear algebra: SVD, PCA,...
- Statistics: summary statistics, hypothesis testing,...
Refer to the MLlib guide for usage examples.
Community
MLlib is developed as part of the Apache Spark project. It thus gets tested and updated with each Spark release.
If you have questions about the library, ask on the Spark mailing lists.
MLlib is still a rapidly growing project and welcomes contributions. If you'd like to submit an algorithm to MLlib, read how to contribute to Spark and send us a patch!
Getting started
To get started with MLlib:
- Download Spark. MLlib is included as a module.
- Read the MLlib guide, which includes various usage examples.
- Learn how to deploy Spark on a cluster if you'd like to run in distributed mode. You can also run locally on a multicore machine without any setup.
Latest News
- Preview release of Spark 4.2.0 (Mar 12, 2026)
- Preview release of Spark 4.2.0 (Feb 08, 2026)
- Spark 4.0.2 released (Feb 05, 2026)
- Spark 3.5.8 released (Jan 15, 2026)
