Flexibility
Seamlessly work with both graphs and collections.
GraphX unifies ETL, exploratory analysis, and iterative graph computation within a single system. You can view the same data as both graphs and collections, transform and join graphs with RDDs efficiently, and write custom iterative graph algorithms using the Pregel API.
messages = spark.textFile("hdfs://...")
graph2 = graph.joinVertices(messages) {
(id, vertex, msg) => ...
}
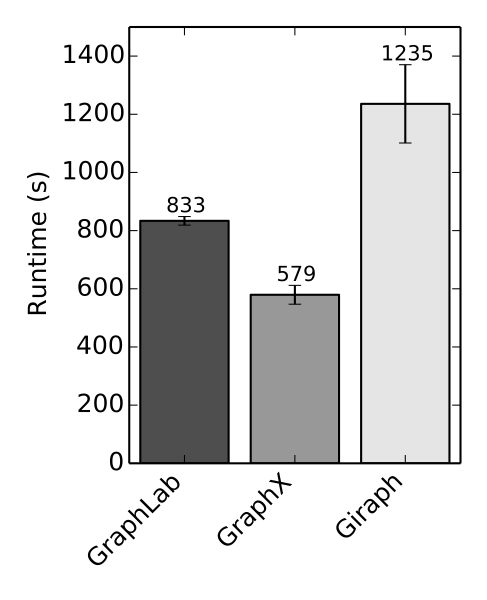
Speed
Comparable performance to the fastest specialized graph processing systems.
GraphX competes on performance with the fastest graph systems while retaining Spark's flexibility, fault tolerance, and ease of use.
Algorithms
Choose from a growing library of graph algorithms.
In addition to a highly flexible API, GraphX comes with a variety of graph algorithms, many of which were contributed by our users.
- PageRank
- Connected components
- Label propagation
- SVD++
- Strongly connected components
- Triangle count
Community
GraphX is developed as part of the Apache Spark project. It thus gets tested and updated with each Spark release.
If you have questions about the library, ask on the Spark mailing lists.
GraphX is in the alpha stage and welcomes contributions. If you'd like to submit a change to GraphX, read how to contribute to Spark and send us a patch!
Getting started
To get started with GraphX:
- Download Spark. GraphX is included as a module.
- Read the GraphX guide, which includes usage examples.
- Learn how to deploy Spark on a cluster if you'd like to run in distributed mode. You can also run locally on a multicore machine without any setup.
Latest News
- Preview release of Spark 4.2.0 (Apr 09, 2026)
- Preview release of Spark 4.2.0 (Mar 12, 2026)
- Preview release of Spark 4.2.0 (Feb 08, 2026)
- Spark 4.0.2 released (Feb 05, 2026)
