Spark Release 0.8.0
Apache Spark 0.8.0 is a major release that includes many new capabilities and usability improvements. It’s also our first release in the Apache incubator. It is the largest Spark release yet, with contributions from 67 developers and 24 companies.
You can download Spark 0.8.0 as either a source package (4 MB tar.gz) or a prebuilt pacakge for Hadoop 1 / CDH3 or CDH4 (125 MB tar.gz). Release signatures and checksums are available at the official Apache download site.
Monitoring UI and Metrics
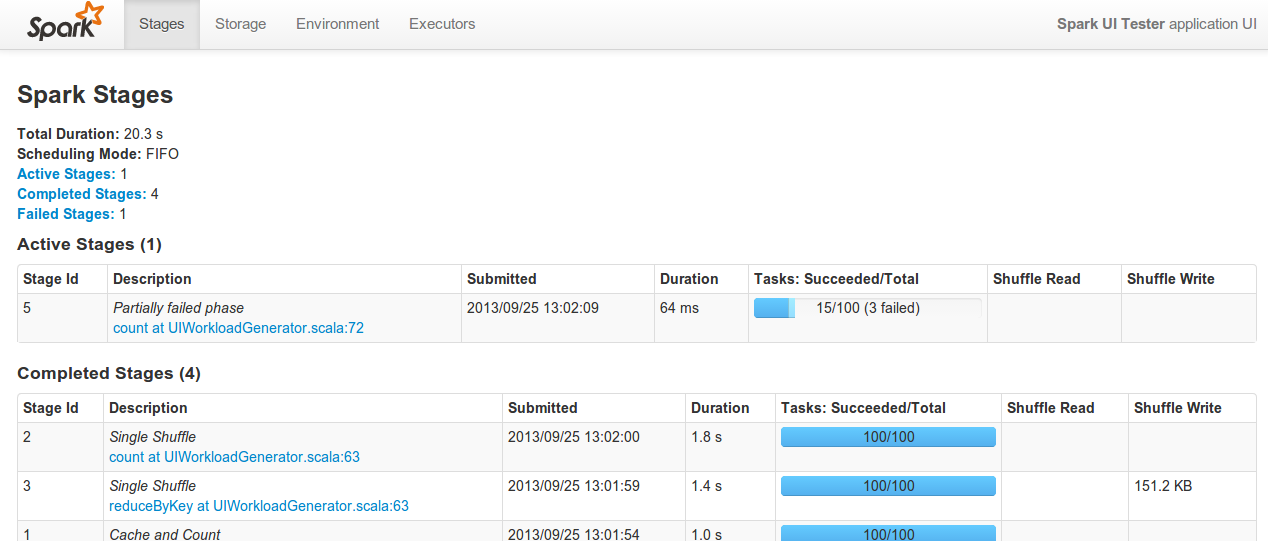
Spark now displays a variety of monitoring data in a web UI (by default at port 4040 on the driver node). A new job dashboard contains information about running, succeeded, and failed jobs, including percentile statistics covering task runtime, shuffled data, and garbage collection. The existing storage dashboard has been extended, and additional pages have been added to display total storage and task information per-executor. Finally, a new metrics library exposes internal Spark metrics through various API’s including JMX and Ganglia.
Machine Learning Library
This release introduces MLlib, a standard library of high-quality machine learning and optimization algorithms for Spark. MLlib was developed in collaboration with the UC Berkeley MLbase project. The current library contains seven algorithms, including support vector machines (SVMs), logistic regression, several regularized variants of linear regression, a clustering algorithm (KMeans), and alternating least squares collaborative filtering.
Python Improvements
The Python API has been extended with many previously missing features. This includes support for different storage levels, sampling, and various missing RDD operators. We’ve also added support for running Spark in IPython, including the IPython Notebook, and for running PySpark on Windows.
Hadoop YARN support
Spark 0.8 add greatly improved support for running standalone Spark jobs on a YARN cluster. The YARN support is no longer experimental but now part of mainline Spark. Support for running against a secured YARN cluster has also been added.
Revamped Job Scheduler
Spark’s internal job scheduler has been refactored and extended to include more sophisticated scheduling policies. In particular, a fair scheduler implementation now allows multiple users to share an instance of Spark, which helps users running shorter jobs to achieve good performance, even when longer-running jobs are running in parallel. Support for topology-aware scheduling has been extended, including the ability to take into account rack locality and support for multiple executors on a single machine.
Easier Deployment and Linking
User programs can now link to Spark no matter which Hadoop version they need, without having to publish a version of spark-core specifically for that Hadoop version. An explanation of how to link against different Hadoop versions is provided here.
Expanded EC2 Capabilities
Spark’s EC2 scripts now support launching in any availability zone. Support has also been added for EC2 instance types which use the newer “HVM” architecture. This includes the cluster compute (cc1/cc2) family of instance types. We’ve also added support for running newer versions of HDFS alongside Spark. Finally, we’ve added the ability to launch clusters with maintenance releases of Spark in addition to launching the newest release.
Improved Documentation
This release adds documentation about cluster hardware provisioning and inter-operation with common Hadoop distributions. Docs are also included to cover the MLlib machine learning functions and new cluster monitoring features. Existing documentation has been updated to reflect changes in building and deploying Spark.
Other Improvements
- RDDs can now manually be dropped from memory with
unpersist. - The RDD class includes the following new operations:
takeOrdered,zipPartitions,top. - A
JobLoggerclass has been added to produce archivable logs of a Spark workload. - The
RDD.coalescefunction now takes into account locality. - The
RDD.pipefunction has been extended to support passing environment variables to child processes. - Hadoop
savefunctions now support an optional compression codec. - You can now create a binary distribution of Spark which depends only on a Java runtime for easier deployment on a cluster.
- The examples build has been isolated from the core build, substantially reducing the potential for dependency conflicts.
- The Spark Streaming Twitter API has been updated to use OAuth authentication instead of the deprecated username/password authentication in Spark 0.7.0.
- Several new example jobs have been added, including PageRank implementations in Java, Scala and Python, examples for accessing HBase and Cassandra, and MLlib examples.
- Support for running on Mesos has been improved – now you can deploy a Spark assembly JAR as part of the Mesos job, instead of having Spark pre-installed on each machine. The default Mesos version has also been updated to 0.13.
- This release includes various optimizations to PySpark and to the job scheduler.
Compatibility
- This release changes Spark’s package name to ‘org.apache.spark’, so those upgrading from Spark 0.7 will need to adjust their imports accordingly. In addition, we’ve moved the
RDDclass to the org.apache.spark.rdd package (it was previously in the top-level package). The Spark artifacts published through Maven have also changed to the new package name. - In the Java API, use of Scala’s
Optionclass has been replaced withOptionalfrom the Guava library. - Linking against Spark for arbitrary Hadoop versions is now possible by specifying a dependency on
hadoop-client, instead of rebuildingspark-coreagainst your version of Hadoop. See the documentation here for details. - If you are building Spark, you’ll now need to run
sbt/sbt assemblyinstead ofpackage.
Credits
Spark 0.8.0 was the result of the largest team of contributors yet. The following developers contributed to this release:
- Andrew Ash – documentation, code cleanup and logging improvements
- Mikhail Bautin – bug fix
- Konstantin Boudnik – Maven build, bug fixes, and documentation
- Ian Buss – sbt configuration improvement
- Evan Chan – API improvement, bug fix, and documentation
- Lian Cheng – bug fix
- Tathagata Das – performance improvement in streaming receiver and streaming bug fix
- Aaron Davidson – Python improvements, bug fix, and unit tests
- Giovanni Delussu – coalesced RDD feature
- Joseph E. Gonzalez – improvement to zipPartitions
- Karen Feng – several improvements to web UI
- Andy Feng – HDFS metrics
- Ali Ghodsi – configuration improvements and locality-aware coalesce
- Christoph Grothaus – bug fix
- Thomas Graves – support for secure YARN cluster and various YARN-related improvements
- Stephen Haberman – bug fix, documentation, and code cleanup
- Mark Hamstra – bug fixes and Maven build
- Benjamin Hindman – Mesos compatibility and documentation
- Liang-Chi Hsieh – bug fixes in build and in YARN mode
- Shane Huang – shuffle improvements, bug fix
- Ethan Jewett – Spark/HBase example
- Holden Karau – bug fix and EC2 improvement
- Kody Koeniger – JDBV RDD implementation
- Andy Konwinski – documentation
- Jey Kottalam – PySpark optimizations, Hadoop agnostic build (lead), and bug fixes
- Andrey Kouznetsov – Bug fix
- S. Kumar – Spark Streaming example
- Ryan LeCompte – topK method optimization and serialization improvements
- Gavin Li – compression codecs and pipe support
- Harold Lim – fair scheduler
- Dmitriy Lyubimov – bug fix
- Chris Mattmann – Apache mentor
- David McCauley – JSON API improvement
- Sean McNamara – added
takeOrderedfunction, bug fixes, and a build fix - Mridul Muralidharan – YARN integration (lead) and scheduler improvements
- Marc Mercer – improvements to UI json output
- Christopher Nguyen – bug fixes
- Erik van Oosten – example fix
- Kay Ousterhout – fix for scheduler regression and bug fixes
- Xinghao Pan – MLLib contributions
- Hiral Patel – bug fix
- James Phillpotts – updated Twitter API for Spark streaming
- Nick Pentreath – scala pageRank example, bagel improvement, and several Java examples
- Alexander Pivovarov – logging improvement and Maven build
- Mike Potts – configuration improvement
- Rohit Rai – Spark/Cassandra example
- Imran Rashid – bug fixes and UI improvement
- Charles Reiss – bug fixes, code cleanup, performance improvements
- Josh Rosen – Python API improvements, Java API improvements, EC2 scripts and bug fixes
- Henry Saputra – Apache mentor
- Jerry Shao – bug fixes, metrics system
- Prashant Sharma – documentation
- Mingfei Shi – joblogger and bug fix
- Andre Schumacher – several PySpark features
- Ginger Smith – MLLib contribution
- Evan Sparks – contributions to MLLib
- Ram Sriharsha – bug fix and RDD removal feature
- Ameet Talwalkar – MLlib contributions
- Roman Tkalenko – code refactoring and cleanup
- Chu Tong – Java PageRank algorithm and bug fix in bash scripts
- Shivaram Venkataraman – bug fixes, contributions to MLLib, netty shuffle fixes, and Java API additions
- Patrick Wendell – release manager, bug fixes, documentation, metrics system, and web UI
- Andrew Xia – fair scheduler (lead), metrics system, and ui improvements
- Reynold Xin – shuffle improvements, bug fixes, code refactoring, usability improvements, MLLib contributions
- Matei Zaharia – MLLib contributions, documentation, examples, UI improvements, PySpark improvements, and bug fixes
- Wu Zeming – bug fix in scheduler
- Bill Zhao – log message improvement
Thanks to everyone who contributed! We’d especially like to thank Patrick Wendell for acting as the release manager for this release.
Latest News
- Preview release of Spark 4.2.0 (Apr 09, 2026)
- Preview release of Spark 4.2.0 (Mar 12, 2026)
- Preview release of Spark 4.2.0 (Feb 08, 2026)
- Spark 4.0.2 released (Feb 05, 2026)
